

Addressing concerns from the non research community
In the news there have been several discussions and published articles about this dataset. Majority of these articles have multiple factual errors which have raised reasonable doubts in the mind of common people. These doubts were visible in the comments made by readers on the published articles. Here we attempt at pointing out these factual errors and clarifying the doubts in the mind of the non research community.
-
Factual Error 1:
The dataset is available publicallyThe dataset has always been and will continue to be accessible only under a restricted license ageement
Even though majority articles have incorrectly claimed that the data was in the “public domain” or publically available over the internet, the dataset has been accessible only under a license agreement. Thus, it was never and will never be in the “public domain.” The license prohibits redistribution without the same terms, so there should be no “public” copies. -
Factual Error 2:
Goverment is using this data.Goverment funded research does not translate to goverment effort to collect data for facial recognition software
Some reports suggest the government is using the data. It is worth noting that the data was never provided to any government agency. Our records suggest that since the collection of this dataset it has never been downloaded by any U.S. government agency. The different funding agencies from the goverment that supported our research, never explicitly requested for the data collection but rather supported the efforts to assess the short coming of the current facial recognition algorithms. These short coming were highlighted in our publication "Unconstrained face detection and open-set face recognition challenge". We hope this dataset will continue to help researchers advance the state of the art face recognition algorithms. -
Factual Error 3:
It was the largest surveillance datasetEven when released this dataset was not even close to being the largest
Some reports incorrectly claimed that as of 2018, our dataset was the "largest surveillance [face recognition] benchmark in the public domain." Even when released the UCCS dataset was not that large, it was not among the ten largest face recognition datasets, and as stated above, it was never in the public domain while most of the other datasets were.
-
Was it IRB approved? In keeping with the Code of Federal Regulations 45 CFR 46.101(b), the collection was reviewed and classified as "exempt" by the campus Institutional Review Board. The exemption was recorded under IRB #07-084, which was filed/approved when we first applied for the initial funding.
Why an Exempt? The dataset was collected by observing people in a public space, where there is no expectation of privacy. Furthermore, we did not interact with the subjects. - How can someone be removed? If a student or community member has concerns that they may be in the data and it may impact them, they are welcome to contact Dr. Boult and have themselves removed. However, since WE HAVE NO NAMES or identifiers of any kind to know who is who, people can only be identified by visual matching. If desired, we can use our facial recognition software to ease the process but for that ironically we will need your picture to remove your pictures. Also, since the dataset is hard and the technology isn't so advanced a face recognition software won't be able to remove all your pictures. This will leave many blurry images that must be reviewed and identified manually. If someone can identifies pictures of themselves, we can delete them from our dataset and contact the researchers who have already downloaded them to do the same.
- Why was the dataset taken down? After there was a publication that analyzed the metadata in the images, we realized the metadata could be used to reduce the search space of likely matches, thus making the existing dataset no longer suitable for competitions. Since it no longer served our research purpose, we took down the current form, but do plan on doing another competition with revised data.
Held in conjunction with workshop on Interactive and Adaptive Learning in an Open World at ECCV 2018
What's Different?
In most face detection/recognition datasets, the majority of images are “posed”, i.e. the subjects know they are being photographed, and/or the images are selected for publication in public media. Hence, blurry, occluded and badly illuminated images are generally uncommon in these datasets. In addition, most of these challenges are close-set, i.e. the list of subjects in the gallery is the same as the one used for testing.
This challenge explores more unconstrained data, by introducing the new UnConstrained College Students (UCCS) dataset, where subjects are photographed using a long-range high-resolution surveillance camera without their knowledge. Faces inside these images are of various poses, and varied levels of blurriness and occlusion. The challenge also creates an open set recognition problem, where unknown people will be seen during testing and must be rejected.
With this challenge, we hope to foster face detection and recognition research towards surveillance applications that are becoming more popular and more required nowadays, and where no automatic recognition algorithm has proven to be useful yet.
UnConstrained College Students (UCCS) Dataset
The UCCS dataset was collected over several months using Canon 7D camera fitted with Sigma 800mm F5.6 EX APO DG HSM lens, taking images at one frame per second, during times when many students were walking on the sidewalk.


Example images of the UCCS dataset. Note that not a single face in these two images is frontal and without occlusion – some have small occlusion, others large; some have significant yaw and pitch angles; and many are blurred.
Capturing of images was performed on 20 different days, between February 2012 and September 2013 covering various weather conditions such as sunny versus snowy days. They also contain various occlusions such as sunglasses, winter caps, fur jackets, etc., and occlusion due to tree branches, poles, etc. To remove the potential bias of using automated face detection (which selects only easy faces), more than 70,000 face regions were hand-cropped. From these, we have labeled in total 1732 identities. Each labeled sequence contains around 10 images. For approximately 20% of the identities, we have sequences from two or more days. Dataset images are in JPG format with an average size of 5184 × 3456.

Different poses and blurriness
We split up the UCCS database into a training, a validation and a test set. In the training and validation set, which is made accessible to the participants at the beginning of the competition, each image is annotated with a list of bounding boxes. Each bounding box is either labeled with an integral identity label, or with the “unknown” label −1. In total, we will provide labels for 1000 different known identities, and around half of the faces in the dataset will be “unknown”. We provide two scripts to run the evaluation on the validation set for part 2 and part 3 respectively, so that participants can optimize meta-parameters of their algorithms to the validation set data. We provide open source baseline algorithms for both parts based on Bob that the participants can compare against.

Sample Bounding Boxes
Note: The samples do not contain the same image resolution as the ones in dataset.
Timeline
Pre-Release Dataset
Available
Challenge Data Release
08/01/2018
Submission deadline
08/19/2018
Dataset Download
File Formats
All files are given / expected in CSV format, maybe with comment lines starting with '#'.Protocol File Formats
For the training and validation set, protocol files contain the complete information of the faces contained in the image. Particularly, they contain a unique number (FACE_ID), the image file name, an integral SUBJECT_ID (which might be -1 for unknown identities) and the hand-labeled face bounding box (FACE_X, FACE_Y, FACE_WIDTH, FACE_HEIGHT).Training/Validation Protocol
| FACE_ID | FILE | SUBJECT_ID | FACE_X | FACE_Y | FACE_WIDTH | FACE_HEIGHT |
|---|---|---|---|---|---|---|
| 6000000 | IMG_5485_30.JPG | 7000000 | 75.6 | 567.4 | 75.9 | 74.4 |
| 6000001 | IMG_5485_30.JPG | 7000001 | 294.4 | 531.6 | 74.4 | 81.8 |
| 6000002 | IMG_5485_30.JPG | 7000002 | 544.4 | 525.7 | 71.4 | 83.3 |
The test set contains only a list of file names, i.e., without any information about faces contained in the image. Particularly, there will be images that do not contain any faces.
Test Protocol
| FILE |
|---|
| 000214cdae7b0687beab37b1fc102958.jpg |
| 000438fc89e6a536919222dab0bf99b9.jpg |
| 0006be8811958bd396baee0960fbe5b3.jpg |
Score File Formats
Face detection score files need to contain one detected bounding box per line. Particularly, each line should contain the FILE (same as in the protocol file), a bounding box (BB_X, BB_Y, BB_WIDTH, BB_HEIGHT) and a confidence score (DETECTION_SCORE). The confidence score can have any range, but higher scores need to mean higher confidences. Note that generally there is more than one bounding box per file. Hence, there should be several lines for each image.
Face Detection Score File
| FILE | BB_X | BB_Y | BB_WIDTH | BB_HEIGHT | DETECTION_SCORE |
|---|---|---|---|---|---|
| IMG_5485_30.JPG | 549.51 | 550.47 | 54.89 | 65.86 | 26.25 |
| IMG_5485_30.JPG | 10.01 | 543.44 | 58.44 | 70.13 | 20.69 |
| IMG_5485_30.JPG | 1447.01 | 98.52 | 70.27 | 84.32 | 20.16 |
The face recognition score file is an extension of the face detection score file. Additionally to the above mentioned bounding boxes, a list of (SUBJECT_ID, RECOGNITION_SCORE)-pairs should be added. We accept up to 10 pairs, i.e., in order to compute detection and identification rate curves for rank up to 10. Please note that only the faces that are labeled with a SUBJECT_ID in the validation set protocol file are of interest. Unknown faces (i.e., faces that have SUBJECT_ID -1 in the protocol file) can either be labeled with -1, or no SUBJECT_ID should be assigned (i.e., no (SUBJECT_ID, RECOGNITION_SCORE)-pair should be given after the DETECTION_SCORE). If any mis-detection (i.e., background region) is labeled with -1 or not labeled at all, this does not count as an error. Any background region or unknown face that is labeled with a SUBJECT_ID other than -1 will increase the number of false alarms (see Evaluation below). If you plan to participate in both challenges, the face recognition score file can be used for evaluating both the detection and the recognition experiment. Hence, only one score file needs to be submitted in this case.
Face Recognition Score File
| FILE | BB_X | BB_Y | BB_WIDTH | BB_HEIGHT | DETECTION_SCORE | SUBJECT_ID_1 | RECOGNITION_SCORE_1 | SUBJECT_ID_2 | RECOGNITION_SCORE_2 | SUBJECT_ID_3 | RECOGNITION_SCORE_3 | ... | ... |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 003b27f9e65f4da9847186cc041ba0ca.jpg | 2511.55 | 3154.04 | 202.72 | 243.26 | 23.86 | 1120 | -61.81 | 1217 | -62.19 | 199 | -61.73 | 41 | -62.41 |
| 003b27f9e65f4da9847186cc041ba0ca.jpg | 960.43 | 1990.14 | 270.26 | 324.32 | 17.69 | -1 | -55.98 | ||||||
| 003b27f9e65f4da9847186cc041ba0ca.jpg | 3811.96 | 1486.11 | 227.54 | 273.05 | 13.05 | 937 | -57.91 | -1 | -66.51 |
Baseline
The baseline face detection and face recognition experiments use the MTCNN-v2 and VGG-v2 detection and recognition pipeline, as implemented in the open-source package written in Python. Parts of this package are using the signal processing and machine learning toolbox Bob. You can downloaded the Baseline package from PyPI.Face Detection Baseline
The baseline face detector simply uses the pre-trained MTCNN-v2 detector models, with the Caffe/Python implementation adapted from http://github.com/walkoncross/mtcnn-caffe-zyf. Since the detector is not optimized for blurry, occluded, or full profile faces, we had to lower the three detection thresholds to (0.1, 0.2, 0.2). If you do not wish to run the baseline face detector, you can download the resulting Baseline face detection score file.Face Recognition Baseline
For face recognition, we use the VGG v2 face recognition pipeline.
We use the pre-trained Squeeze and Excite VGG v2 network and extract the features from the 'pool5/7x7_s1' layer.
For each person, the features of the training set are averaged to build a template of that person.
Open-set recognition is performed by averaging all training features of unknown identities in a separate template, and another template for features extracted from background detections of the MTCNN detector.
First, the faces in the training images are re-detected, to assure that the bounding boxes of training and test images have similar content.
Then, the faces are rescaled and cropped to a resolution of 224x224 pixels.
Afterwards, features are extracted using the VGG v2 network.
For each identity (including the unknown identity -1 and background detections -2), the average of the features is stored as a template.
During testing, in each image all faces are detected, cropped, and features are extracted.
Those probe features are compared to all templates using cosine similarity.
For each detected face, the 10 identities with the smallest distances are obtained -- if identity -1 or -100 is included, all less similar identities are not considered anymore.
If you do not wish to run the baseline face recognition system, you can download the resulting Baseline face recognition score file.
Evaluation
The evaluation will use Free Receiver Operator Characteristic (FROC) to evaluate the face detection experiments, and the Detection and Identification Rate (DIR) curve on Rank 1 to evaluate open set face recognition.
Learning from our first challenge, in both we use the total number of False Alarms or False Identifications, respectively, in logarithmic scale on the x-axis; and the Detection Rate or Detection and Identification Rate, respectively, on the y-axis.
The dotted gray line represents equal number of false and correct detections or identifications, respectively.
An implementation of the two evaluation scripts for the validation set is provided in the Baseline package.
Please refer to this package for more details about the evaluation.
For comparison, the FROC and DIR plots of the baseline are:
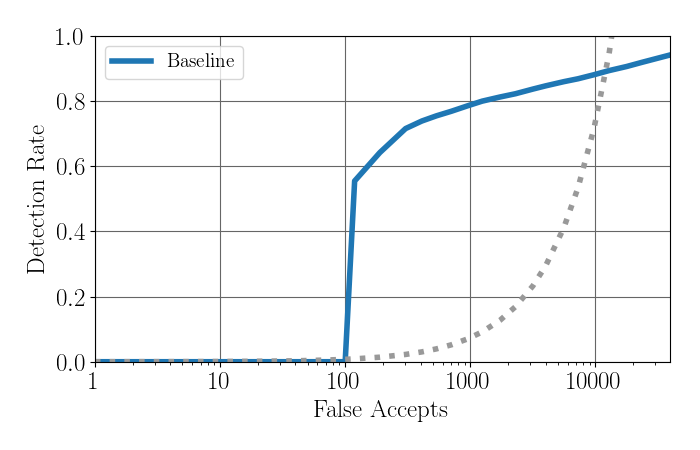
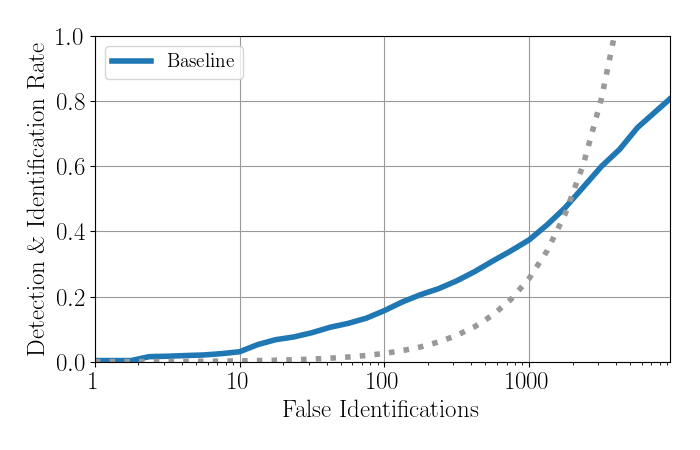
Evaluation results on validation set
Contact Us
Organization Team
Dr. Terrance E. Boult Website
Dr. Manuel Günther Website
Akshay Raj Dhamija Website