
FLEXIBLE IMAGING SYSTEMS
Report 5/2004
DARPA HID program contract number N00014-00-1-0929
Principal Investigators:
Terrence E. Boult
Department of Computer Science
University of Colorado at Colorado Springs
1420 Austin Bluffs Parkway
Colorado Springs CO 80933-7150
Fax 719 262 3900
Email: tboult@cs.uccs.edu
Shree K. Nayar
1214 Amsterdam Avenue
Department of Computer Science, Columbia University
New York, NY 10027.
Phone: 212-939-7092
Fax: 212-939-7172
Email: nayar@cs.columbia.edu
2. Omni-directional and Super wide field-of-view Sensors for HID 2
3. Surveillance Issues in HID 7
4. Synthetic Sensor Evaluations 8
6. Evaluation and prediction 17
1.Overview:
Typical pan-tilt-zoom sensors have a five to fifty degree field of view, and track a single target. Not only is locating and retaining a facial target over a large range difficult, but also limited by sensor parameters. To address these limitations, this project designed, developed, and implemented new catadioptric omnidirectional sensors capable of a large effective optical zoom. The fundamental feature underlying the sensors is the ability to transition between an omnidirectional image and a fine resolution image for use in a HID system.
The first sensor, dubbed the Zoomnicam uses a combination of catadioptrics and a physical zoom. By physically zooming into different parts of an omnidirectional image, the effective Zoomnicam field of view ranges between 360 to 15 degrees. The second alternative is using Mega-Pixel digital still cameras. It is our hypothesis that if the resolution on the face is approximately the same, the sensors will have the same performance in facial recognition across these sensors and will be comparable to traditional cameras.
Field of view, however, is not the only senor parameter that impacts recognition. The project evaluated a number of potential sensor parameters, blur, gamma, compression, dynamic range for the impact on face recognition. These synthetic sensor evaluations help direct other aspects of the project and also answered important questions about the impact of blur, gamma, dynamic range and compression on the resulting images.
Our analysis and experimentation made it very clear that dynamic range was a significant issue and it probably is a major factor in why outdoor face recognition is so much weaker than indoor. This led us to design and development of sensors for adaptive dynamic range, and for studying other approaches for improving dynamic range for HID.
Finally, there is the need for a method to evaluate the efficacy of the new sensors. Previous HID system evaluation has focused on algorithm evaluation. In algorithm evaluation, the only parameters varied are the algorithms themselves. Sensor evaluation introduces significantly more degrees of freedom in HID system input and, more importantly, makes it impossible to test with identical inputs. To address these issues, we developed a new evaluation paradigm defined with statistical confidence measures. In addition we developed techniques to predict when face-recognition system were going to fail, then found ways, at the system level, to help reduce those failures.
We briefly review the project results in each of these areas. For details see the papers in the reference sections, which also relate our work to others in the field.
2.Omni-directional and Super wide field-of-view Sensors for HID:
For flexible imaging we have undertaken 3 data collections, (omni-directional, zoomnicam and long-distance), with the resulting data submitted as part of the DARPA HBASE, and also available directly from Dr. Boult. These are in addition the much larger photo-head dataset, which is used both in this project and the Columbia lead Vision in Bad Weather project. Combined these were almost a Terabyte of test data exploring sensor design, resolution, lighting distance and weather effects. We briefly review those sensors, the experiments and the results.
|
|

The first of our non-traditional sensor projects sought to address the question of how well an omni-directional camera could be use for face recognition. To allow it to operate over a wider range of distance we chose to use a 3.1 Megapixel camera, the Nikon 990. The omni-directional images were obtained using Remote Reality’s OneShot lens attached to the Nikon 990. Dr. Boult and students developed Linux software that controlled the Nikon 990 camera being used and combined video rate person tracking (using its analog TV output) with high-resolution image capture to provide face images suitable for recognition. While the camera supported un-compressed TIFFs, the project always used the high-resolution jpeg format. This software simplified our data collection process and was used in four different data collections at NIST. In
|
|

all but one collection the subject stood at fixed distances to support repeatable measurements.
 In the collections there are multiple images of each subject at each setting with over 8000 images in total. Variations included view angle, lighting (artificial and natural), distance and time. Standard camera images of each subject were also available.
In the collections there are multiple images of each subject at each setting with over 8000 images in total. Variations included view angle, lighting (artificial and natural), distance and time. Standard camera images of each subject were also available.
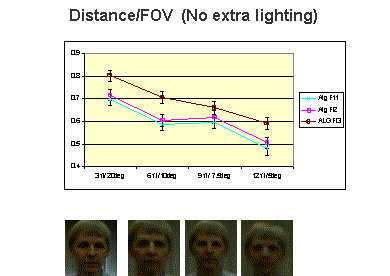
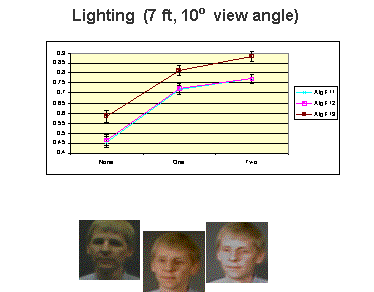
Two examples of the analysis are shown above, with the example subject’s gallery image shown in the middle. The left show face recognition performances at off angle viewing of 10 degrees as the number of additional lights are added. The images were taken with a fixed aperture and shutter speed so that the brightness variations are not masked by automatic gain controls. The three graphs are for variations of the matching algorithms in the FactIt SDK, with the algorithm F13 the algorithm using full template matching and the other two using smaller (faster) templates. The error bars show 95% confidence intervals computed using the BRR we presented in [Micheal-Boult-01]. With two lights, consistent with what is used in the standard images and gallery, the recognition rate for the unwarped omni-directional images are approximately 90%, consistent with off axis regular images of comparable resolution. The second examples considered the impact the graph on the right shows the impact of distance on recognition from omni-directional cameras in ambient lighting conditions. It is clear the images are quite dark, yet the recognition rates are reasonable. It is important to remember these are omni-directional images, with the face image cropped from that, so one might interpret the results as suggesting the system could recognize 60% of all the people within 12ft of the camera, and 70% of those within 6ft. Combining the results with the omni-directional imaging with lighting results its clear that in a well-lit area the system can increase that to near 90% recognition. The results show that omni-directional sensors have potential for human identification at a distance.
 The second flexible imaging sensor explored was an omni-directional system capable of zooming, or a zoomnicamera. Design and implementation of the zoomnicam prototype was done at Columbia. The unit uses a Sony DFW-V500 color zoom and a relay lens to make the imaging approximately telecentric and allow it to focus on the nearby parabolic mirror. The mirror was mounted on a xy-stage with 4” motion, though most motions were much smaller and hence much faster than a traditional Pan/Tilt system. Dr. Nayar and the team at Columbia developed a controller for the stage and calibration software that allowed unwarping the resulting image to a perspectively correct image. The unit was transfer to Dr. Boult and students at Lehigh where the control software was extended to support facial image collections and experiments.
The second flexible imaging sensor explored was an omni-directional system capable of zooming, or a zoomnicamera. Design and implementation of the zoomnicam prototype was done at Columbia. The unit uses a Sony DFW-V500 color zoom and a relay lens to make the imaging approximately telecentric and allow it to focus on the nearby parabolic mirror. The mirror was mounted on a xy-stage with 4” motion, though most motions were much smaller and hence much faster than a traditional Pan/Tilt system. Dr. Nayar and the team at Columbia developed a controller for the stage and calibration software that allowed unwarping the resulting image to a perspectively correct image. The unit was transfer to Dr. Boult and students at Lehigh where the control software was extended to support facial image collections and experiments.
 Again real-time tracking was possible from the video output, but the focus of this project was the facial recognition. The Zoomnicam data was collected on two different dates, imaging stationary subjects at 4 or 5 distances producing a total collection of over 2000 image from 85 subjects with 72 overlapping between the collections. In addition to the zoomnicamera images, all subjects had same and different day traditional camera images taken as part of parallel collections at NIST and most also were imaged by the mega-pixel omni-directional system. This figure shows a standard camera image (upper left) from 3 feet and then a range of zoomnicameras at distances from 6 to 15 feet. Note how the zoomincam images also have strong directional lighting effects, effects that would impact the recognition rate of standard face recognition.
Again real-time tracking was possible from the video output, but the focus of this project was the facial recognition. The Zoomnicam data was collected on two different dates, imaging stationary subjects at 4 or 5 distances producing a total collection of over 2000 image from 85 subjects with 72 overlapping between the collections. In addition to the zoomnicamera images, all subjects had same and different day traditional camera images taken as part of parallel collections at NIST and most also were imaged by the mega-pixel omni-directional system. This figure shows a standard camera image (upper left) from 3 feet and then a range of zoomnicameras at distances from 6 to 15 feet. Note how the zoomincam images also have strong directional lighting effects, effects that would impact the recognition rate of standard face recognition.
|
|
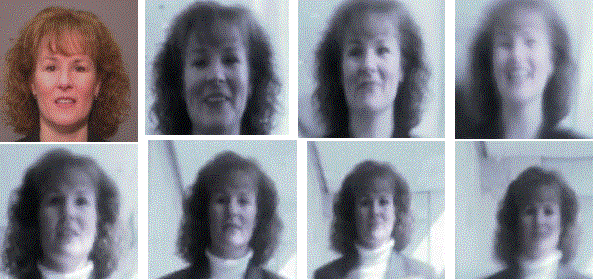
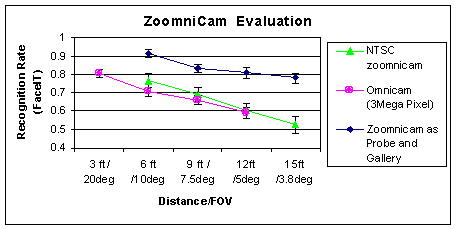 Using the results of these data collections were have been addressing the facial recognition quality of these sensors. The experimental analysis was to test the hypothesis that the zoomnicamera, when it was zoomed to provide a similar resolution as the MegaPixel omni-camera would have essentially the same recognition rate. Since the first experiments showed the omnicamera in a wide-range of settings, a smaller set of experiments were done with the zoomnicameras. The next graph summarizes these results. The error bars show the results of our STRAT/BRR technique for performance analysis, allowing us to draw conclusions across different data sets. Clearly the two curves are not statistically different. The upper curve shows the results when the zoomnicamera data was used as both probe and gallery images. Multiple images were taken so it is different images in the probe/gallery, but they have similar lighting. This suggests that lighting is a much stronger factor than the difference in sensors.
Using the results of these data collections were have been addressing the facial recognition quality of these sensors. The experimental analysis was to test the hypothesis that the zoomnicamera, when it was zoomed to provide a similar resolution as the MegaPixel omni-camera would have essentially the same recognition rate. Since the first experiments showed the omnicamera in a wide-range of settings, a smaller set of experiments were done with the zoomnicameras. The next graph summarizes these results. The error bars show the results of our STRAT/BRR technique for performance analysis, allowing us to draw conclusions across different data sets. Clearly the two curves are not statistically different. The upper curve shows the results when the zoomnicamera data was used as both probe and gallery images. Multiple images were taken so it is different images in the probe/gallery, but they have similar lighting. This suggests that lighting is a much stronger factor than the difference in sensors.
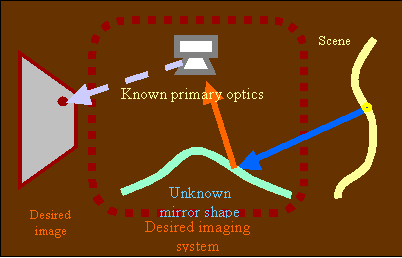 Ultra-wide field of view is not the only issue for sensors for HID. We can think of the omni-directional sensor as a special case of defining mapping from the scene to an image. Dr. Nayar and students at Columbia developed a general approach to catadioptric system design that allows them to solve for the mirror shape for any given image-to-scene mapping. Using such a flexible system one might desire an Anamorphic imaging system where the mirror is such that faces at expected distances all have the same size. Such an example is show here where the faces in the bottom for of people are show for a perspective image and for an anamorphic system. This is only one of infinitely many constraints that might be imposed on the scene to image mapping and then realized using the general imaging theory developed.
Ultra-wide field of view is not the only issue for sensors for HID. We can think of the omni-directional sensor as a special case of defining mapping from the scene to an image. Dr. Nayar and students at Columbia developed a general approach to catadioptric system design that allows them to solve for the mirror shape for any given image-to-scene mapping. Using such a flexible system one might desire an Anamorphic imaging system where the mirror is such that faces at expected distances all have the same size. Such an example is show here where the faces in the bottom for of people are show for a perspective image and for an anamorphic system. This is only one of infinitely many constraints that might be imposed on the scene to image mapping and then realized using the general imaging theory developed.
|
|

3.Surveillance Issues in HID
In the final year of the Flexible imaging project Dr. Boult and students instituted a new direction, building on our earlier work in visual surveillance we began looking at issues for recognition of particular human activities. The work builds on our geo-spatial detection and tracking work, which began as part of the DARPA VSAM program. With regard to wide-area sensing and detailed assessment Dr. Boult, as part of the Army SmartSensorWeb(SSW) program, extended his system for tracking using a 360FOV camera. Not only did it detect and track targets, it geo-located their position and used that to pass-off targets to a PTZ that could then be used for detailed assessment. The omni-directional video supports tracking multiple simultaneously and is very useful for crowded areas
While detection and tracking still needs research, especially for following individuals within crowds, we postulate that it is not the most significant problem. More important is developing an approach that allows one to specify what activity is of interest and recognize complex activities. Well known models used for event and anomaly detection, such as Hidden Markov Models (HMMS) or stochastic grammars, both require lots of training data and are very difficult to use, even for expert computer users. In a recent study, we had graduate students in CS and EE learn to use an HMM system, then use it to specify/learn simple events. After training, those who could figure out how to specify given events took more than 25min, on average, to specify a single event of interest. Furthermore, 13 of the 20 students unable develop HMM for the relatively simple events within an hour.
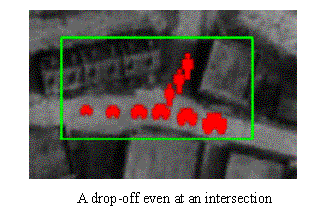
 We proposed [Yu-Boult-2003] a radically new approach, UI-GUI: Image Understanding of Graphical User Interfaces, which offers a new solution and significant promise for human activity recognition. The approach ties the “event recognition” to the GUI display of targets and sensory data. The definition of an event is done using what the end-user sees in the GUI (so it still depends on good low-level processing), and combines different icons in spatio-temporal patterns. This figure is an example from our video tracking, with target type and localization is displayed graphically. The rule (the box) looks for someone being dropped off. Furthermore, the IUGUI supports effective in-the-field sensor integration – if the results from new senor can be displayed on the users screen it can be used as part of an IU-GUI rule.
We proposed [Yu-Boult-2003] a radically new approach, UI-GUI: Image Understanding of Graphical User Interfaces, which offers a new solution and significant promise for human activity recognition. The approach ties the “event recognition” to the GUI display of targets and sensory data. The definition of an event is done using what the end-user sees in the GUI (so it still depends on good low-level processing), and combines different icons in spatio-temporal patterns. This figure is an example from our video tracking, with target type and localization is displayed graphically. The rule (the box) looks for someone being dropped off. Furthermore, the IUGUI supports effective in-the-field sensor integration – if the results from new senor can be displayed on the users screen it can be used as part of an IU-GUI rule.
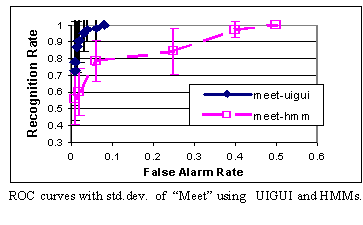
Using the IUGUI approach, the same 20 students as above were trained to use the system, in under 5 min, and specified each of their activities of interest in, on average, 11 seconds. That is 10000 times faster than using HMMs. Here we show an ROC curve of performance, and clearly of the UI-GUI was also significantly better than HMM. While preliminary, these early experiments show the approach is very significant potential for activity recognition.
4. Synthetic Sensor Evaluations
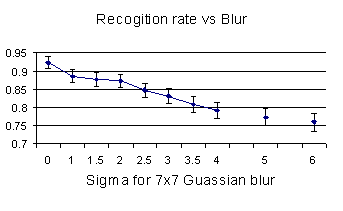 We also pursued a collection of “simulation” experiments were simulated sensor effects were applied to a subset of the FERET data. The subset consists of 256 subjects with 4 images per person, to permit the use of STRAT for estimate of confidence intervals. The first three of these synthetic experiments examined the impact of blur, gamma, and compression. Spatial blurring was done using 7×7 windows with an approximate Gaussian of a given standard deviation (sigma) given in pixel. The results for were not surprising, showing the expected impact of blur, which was statistically significant even for a single pixel sigma. While there have been other informal reports of blur improving results our results did not find such a pattern. Again each bar in the graph is a 95% confidence interval from STRAT/BRR.
We also pursued a collection of “simulation” experiments were simulated sensor effects were applied to a subset of the FERET data. The subset consists of 256 subjects with 4 images per person, to permit the use of STRAT for estimate of confidence intervals. The first three of these synthetic experiments examined the impact of blur, gamma, and compression. Spatial blurring was done using 7×7 windows with an approximate Gaussian of a given standard deviation (sigma) given in pixel. The results for were not surprising, showing the expected impact of blur, which was statistically significant even for a single pixel sigma. While there have been other informal reports of blur improving results our results did not find such a pattern. Again each bar in the graph is a 95% confidence interval from STRAT/BRR.
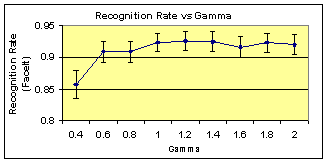 In the analysis for gamma, the simulations do not have the ability to change the gamma at capture time, rather they are reprocessed images from good quality images with moderate dynamic range but unknown gamma (the original FERET images used were digitized from film). Thus it is not a measure of the impact of improved dynamic range, but only the results of brightness variations. The images were gamma corrected with gamma=1 equal to the original image.
In the analysis for gamma, the simulations do not have the ability to change the gamma at capture time, rather they are reprocessed images from good quality images with moderate dynamic range but unknown gamma (the original FERET images used were digitized from film). Thus it is not a measure of the impact of improved dynamic range, but only the results of brightness variations. The images were gamma corrected with gamma=1 equal to the original image.
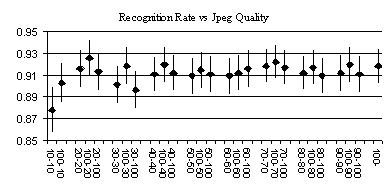 The analysis for the jpeg compression did present some unexpected results. The images uses were uncompressed FERET images that were converted from film. The results considered compression of the gallery (first number in the pair), the probe (second number) or both gallery and probe. So the entry for 90-100 is the recognition rate (.91) for a gallery compressed with jpeg quality = 90, and a problem with jpeg quality=100. The unexpected result was that there was no statistically significant difference between compressions from 100 down to 20.
The analysis for the jpeg compression did present some unexpected results. The images uses were uncompressed FERET images that were converted from film. The results considered compression of the gallery (first number in the pair), the probe (second number) or both gallery and probe. So the entry for 90-100 is the recognition rate (.91) for a gallery compressed with jpeg quality = 90, and a problem with jpeg quality=100. The unexpected result was that there was no statistically significant difference between compressions from 100 down to 20.
Super-Resolution. An important aspect of the early aspect of the project was to determing the impact of resolution, including testing if super-resolution would improve recognition rates. To answer this we implemented a system for face-image super-resolution using the integrating resampler we developed earlier DARPA funding and tested it with FaceIt and a NIST supplied PCA-based algorithm as the recognition cores. Early work used the approach has been demonstrated for algorithm comparison (Visionics FaceIt versus PCA systems) and to determine the number ching information would be known precisely.
|
|

Left shows ooriginal low-resolution images. Middle is bilinear-based super resolution and right is integrating resampler-based super-resolution. The bilinear approach shows noticeable artifacts and was not statistically superior to the raw images for recognition. Integrating resampler-based super-resolution was, however, statistically significantly better than raw images for FaceIT and PCA-based face recognition algorithms.
The experimental results, summarized in [Boult-Chiang-Micheals-01], showed that super-resolution with the integrating resampler was superior, in a statistically significant manner, to bilinear warping based super-resolution, and to pure image interpolation. Furthermore the work showed that super-resolution using simple bilinear warping was not significantly better than raw images. While consistent with other observations that (simple) super resolution may not improve performance of face recognition systems. The work showed that there is potential for super-resolution, when done right, to increase performance
5. Dynamic Range
The final set of synthetic experiments looked at dynamic range, consider standard dynamic range and a new “adaptive” dynamic range. In these experiments we scaled the “radiance” (i.e. values) of the images and also limited their dynamic range. For the simple “static” case we scaled the image and then kept first n bits, e.g. for a scaling of .5 and 4 bpp, we would take ((( I )>>5)<<4) for each pixel in the image This is shown on the left side of the following figure for 7bpp and 4bpp respectively.. For the “adaptive” approach we scaled the image, but for each pixel we retained the leading N non-zero bits. This approach, which we call adaptive dynamic range, is shown on the right of the following figure with 4bpp and 7bpp respectively. This model was explored because we were developing sensors that could produce this type of image. Using a spatial-light modulator, the scene intensity is reduced in a spatially varying pattern, allowing the captured images to use the dynamic range of the actual cameras. For a real system the goal is to modulate the signal so the full 8 bits of a standard can effectively image the face. The goals of the simulations were help verify the approach’s potential before building the sensor.
|
|
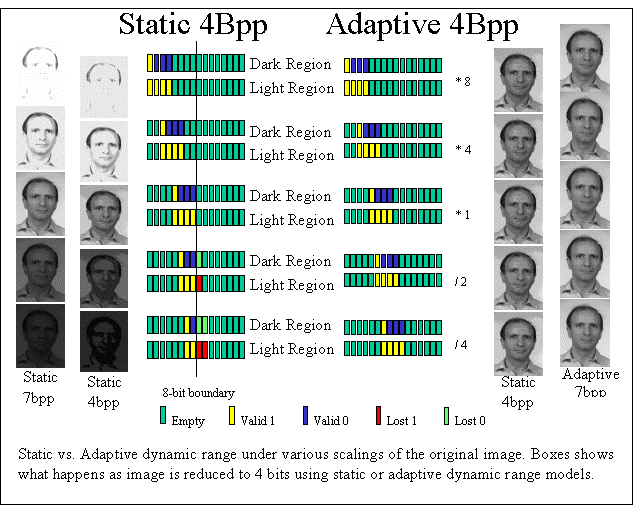
 As is evident from the example images, the adaptive approach does a much better job of retaining the inherent content of the image as it undergoes significant radiance scaling. This adaptive approach was intended to simulate the type of dynamic range we expect for the new adaptive high dynamic range sensing technology.
As is evident from the example images, the adaptive approach does a much better job of retaining the inherent content of the image as it undergoes significant radiance scaling. This adaptive approach was intended to simulate the type of dynamic range we expect for the new adaptive high dynamic range sensing technology.
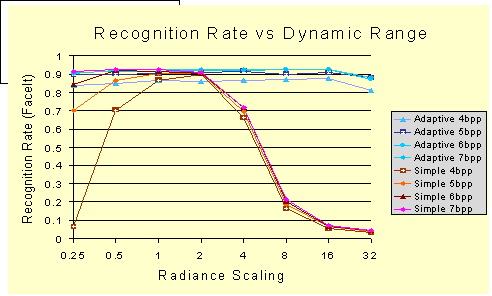
Using these two different models we simulated sensors with different bpp and scaling and then considered the impact on face recognition. The following graph verifies that the intuitive “better” images produced by adaptive dynamic range showed little variation over a wide range of radiance scaling, while the recognition rates for the simple (static) dynamic range breaks down quickly with variation in input radiance.
Dr. Nayar and students at Columbia build the first of the sensors using spatial light modulators to improve dynamic range, using the idea of inserting an attenuator element before the imaging system [Nayer-Banzoi-03]. The system was built using an LCD as the attenuator, placed in front of the imaging system optics. The placement restricted the resolution of the attenuation because the attenuator is inherently blurred by the optics. An example scene is shown where the subjects’ hands are visible but the paper is totally saturated. The LCD attenuation mask and the resulting adaptive dynamic range image are shown.
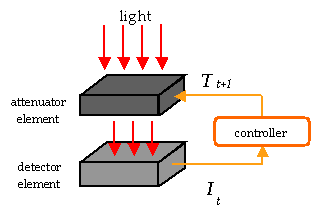


 One of the major problems with the LCD based approach dynamic range approach was the limitation caused by blurring of the attenuator. Drs Nayar and Boult and student designed and built (using funding from another ONR project) a more advanced adaptive dynamic range camera using a digital Mirror device (DMD) mirror system [Banzoi-Nayar-Boult-04]. To allow the system to have sharp focus and have a sharp attenuation mask, the scene is focused on the mirror, and then the imaging system e-images the mirror surfaces.
One of the major problems with the LCD based approach dynamic range approach was the limitation caused by blurring of the attenuator. Drs Nayar and Boult and student designed and built (using funding from another ONR project) a more advanced adaptive dynamic range camera using a digital Mirror device (DMD) mirror system [Banzoi-Nayar-Boult-04]. To allow the system to have sharp focus and have a sharp attenuation mask, the scene is focused on the mirror, and then the imaging system e-images the mirror surfaces.
A prototype system was built using a DMD from a DLP projector, supplying the control signal as a VGA signal to the projector. After calibration to determine the mapping between DMD pixels and camera pixels the system allows for very sharp modulation. Wit the 8 bits of modulation possible from the projector, combined with the 8 bits of camera data the result is an adaptive dynamic range sensor with three orders of magnitude increase in effective dynamic range. Because the DMD can change the modulation at frame rates, the project also explored using spatio-temporally varying patterns that are nearly invisible in the video but permit computation of higher dynamic range images. We also explored using it for computation “filtered” images, e.g. producing edge-images using sub-pixel level modulation. Finally, using the modulator as a “convolution” unit it is possible to use it directly for template matching. Using an eigen-decomposition of the targets of interest, in this case a collection of faces, the system can optically compute the “dot product” of an input signal with the mask with the “result” being directly measured in the image. By placing the same subjects image on a screen imaged by the DMD-based imager it is possible to generate multiple projections at the same time. The result allows the system to do the most expensive step of a PCA-based face recognition system in optics. The technique and examples are presented in [Banzoi-Nayar-Boult-04].


Example of Face recognition using our programmable imaging sensor built from a computer controlled DMD projector
|
|

 Building sensors is not the only aspect of high-dynamic range imaging explored in the project. Dr. Nayar and the group at Columbia also studied the general issues of combining multiple images for dynamic range and issues related to the camera response function. They extended prior work on spatial varying exposures, which was also used in the DMD system above. More significantly they developed a theory for the space of response functions of imagers and calibration techniques to improve the linearization of high-dynamic-range images computed from multiple exposures of non-linear camera. In particular they show the derivative of the local response function drives the distance between measurements and hence the resolution of dynamic range in the resulting image. The results theory provides guidance in how to select different ranges for producing a better high dynamic range from a collection of lower-dynamic range images.
Building sensors is not the only aspect of high-dynamic range imaging explored in the project. Dr. Nayar and the group at Columbia also studied the general issues of combining multiple images for dynamic range and issues related to the camera response function. They extended prior work on spatial varying exposures, which was also used in the DMD system above. More significantly they developed a theory for the space of response functions of imagers and calibration techniques to improve the linearization of high-dynamic-range images computed from multiple exposures of non-linear camera. In particular they show the derivative of the local response function drives the distance between measurements and hence the resolution of dynamic range in the resulting image. The results theory provides guidance in how to select different ranges for producing a better high dynamic range from a collection of lower-dynamic range images.
See [Grossberg-Nayar-02, Grossberg-Nayar-03].
 Exploring the HID applications of spatial varying exposure Dr. Boult and students then began applying the concept to face recognition. Implementing the type of a spatial-varying exposure (SVE) sensor designed at Columbia, which requires a per-pixel “density” mask, is well beyond a standard university fabrication facility. However, Dr. Boult realized that inherent in any RGB Bayer patterned camera, the dominant type of single-chip RGB camera, there is an inherent variation in sensitivity within the color mask. When processed by the DSP in the camera the result is balanced, but as seen in this example the raw measurements are very different. Hence for relatively uniformly colored objects, such as faces, there is the potential to use the Bayer pattern as a crude SVE sensor and then explore techniques for fusion of that data.
Exploring the HID applications of spatial varying exposure Dr. Boult and students then began applying the concept to face recognition. Implementing the type of a spatial-varying exposure (SVE) sensor designed at Columbia, which requires a per-pixel “density” mask, is well beyond a standard university fabrication facility. However, Dr. Boult realized that inherent in any RGB Bayer patterned camera, the dominant type of single-chip RGB camera, there is an inherent variation in sensitivity within the color mask. When processed by the DSP in the camera the result is balanced, but as seen in this example the raw measurements are very different. Hence for relatively uniformly colored objects, such as faces, there is the potential to use the Bayer pattern as a crude SVE sensor and then explore techniques for fusion of that data.
The following tables show recognition rates for two views of subjects in different outdoor experiments. The table shows recognition rates using FaceIT over a subject base of 151 people. The gallery images were taken with a 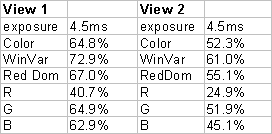 different camera under different lighting conditions, while the probe images were taken outdoors with the subjects facing the sun (view1) and facing perpendicular to the sun (view 2) that casts more complex shadows. The camera used was a DragonFly 1394 Firewire camera that allowed access to the raw Bayer Pattern data. The system was run on the color images (produced by PointGrays’s software for their DragonFly camera) on each of the individual R,G and B channel images and on two different fusion algorithms. The above images show the data for an example subject (In the same order as the table.). It is clear that the red channel sees through the glasses and the shadows of the eyes, but provides little detail anywhere else. The first fusion algorithm, WinVar, was the most effective approach. Fusion was done by computing the variance over a 7×7 window in each of the three channels and then building a fused image retaining the pixel from the channel with largest window variance. The fused images have both significant details in the eye regions as in the rest of the face. The RedDom line represents a fusion where the three channels are combined in a weighted fashion, but were the channel weights are non-linear and weights for are strongly dominated by red when the G/B pixels were dark (allowing better imaging within the shadows). While still preliminary, these results suggest a potential improvement in face recognition outdoors using simple pixel-level fusion from the SVE inherent in Bayer pattern cameras. Exploration of the fusion techniques is still ongoing.
different camera under different lighting conditions, while the probe images were taken outdoors with the subjects facing the sun (view1) and facing perpendicular to the sun (view 2) that casts more complex shadows. The camera used was a DragonFly 1394 Firewire camera that allowed access to the raw Bayer Pattern data. The system was run on the color images (produced by PointGrays’s software for their DragonFly camera) on each of the individual R,G and B channel images and on two different fusion algorithms. The above images show the data for an example subject (In the same order as the table.). It is clear that the red channel sees through the glasses and the shadows of the eyes, but provides little detail anywhere else. The first fusion algorithm, WinVar, was the most effective approach. Fusion was done by computing the variance over a 7×7 window in each of the three channels and then building a fused image retaining the pixel from the channel with largest window variance. The fused images have both significant details in the eye regions as in the rest of the face. The RedDom line represents a fusion where the three channels are combined in a weighted fashion, but were the channel weights are non-linear and weights for are strongly dominated by red when the G/B pixels were dark (allowing better imaging within the shadows). While still preliminary, these results suggest a potential improvement in face recognition outdoors using simple pixel-level fusion from the SVE inherent in Bayer pattern cameras. Exploration of the fusion techniques is still ongoing.

6. Evaluation and prediction
At the core of any scientific process is the ability to evaluate the results and make predictions.
Our project has developed new techniques for both evaluation and performance prediction.
Given a set of samples from a single class, inputting each image to a classifier defines an empirical distribution over the set of class labels. This distribution, which summarizes this class’ behavior conditioned on the algorithm and training set, is, for the purposes of evaluation, further transformed into some error distribution, indicating some degree of “correctness” for a given class. We cannot expect that each class produces the same error distribution. Therefore, given a set of samples from multiple classes, we expect this final, conglomerate error distribution to be composed of many modes (numbering at most the number of classes).
This multi-modality suggests that an evaluation of classification or recognition systems (which we treat similarly) should address two important issues. First, as with most multi-modal distributions, we must apply meaningful statistics. For example, instead of simply estimating the distribution’s overall mean, we instead, should try to locate the central values of the individual modes. Second, in acknowledging the multi-modality, we should, during performance evaluation, exploit any available auxiliary information to enhance the accuracy of our evaluation. Results either knowingly or hypothetically obtained from the same class should be grouped together, and the integrity of these groups should be respected throughout the entire evaluation. One of the goals of our methodology is acknowledgment of these groupings to increase the precision of our second moment statistics.
A new evaluation methodology, based on stratified sampling and balanced repeated resampling (BRR) has been developed and refined. The new methodology is particularly well suited towards sensor and/or image processing evaluation. We have implemented our evaluation methodology using Visionics’ FaceIt and a NIST supplied PCA-based algorithm as the recognition cores. Early work used the approach has been demonstrated for algorithm comparison (Visionics FaceIt versus PCA systems) and to determine the number of images per subject needed for meaningful evaluations(4). Using this paradigm, we can produce FERET-style comparison curves, with confidence intervals for each data point.
|
|
|
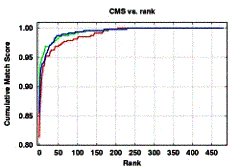 (a)
(a)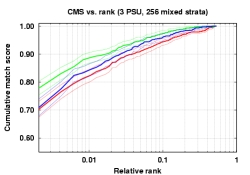
Traditional FERET evaluation curves (a) and curves from the new methodology (b).
We have shown [Micheals-Boult-01] that increased accuracy may be achieved through the use of stratified sampling and the application of a previously overlooked replicate statistical technique known as balanced repeated resampling or BRR. Unlike the bootstrap and/or jackknife methods suggested by others, our new methodology (also used in [Boult-Chang-Micheals-01] may be used to fully exploit ground truth information. The most critical aspect of this work is recognizing that errors in biometrics cannot be expected to be independent and identically distributed, and that any evaluation paradigm that depends on that assumption (e.g. Bernoulli, Bootstrap, Jackknife) will produce misleading results.
In [Micheals-Boult-01] we described the technique and applied to analysis of FERET data with both FaceIT and PCA-based recognition systems. We empirically showed its advantages compared to Jackknife and bootstrap. We also describe the “gallery effect” and show it is statically significant. The effect occurs when there are multiple images of a subject, the choice of images for the gallery is important. The more “neutral” expressions provide for a better gallery (we hypothesize because it is less distant to any of the other facial expressions). Later work by others that claimed “smiling faces” are easier to recognize failed (though they did not show it statically) ignored the fact that to “recognize” the smiling faces they also ended up putting the neutral faces in the gallery, and that in a sense the neutral faces were actually the easier ones to recognize.
This evaluation paradigm has been used for almost all evaluations of our research has used variations of this evaluation approach. As we continued to evolve the technique so it could be more easily used. Eventually developing an approach that does not require multiple images per person, but required larger numbers of people in the evaluation approach and then clustering of partial results to produce estimates. The projects efforts in evaluations, and how to estimate error intervals, eventually lead to the techniques used to estimate error intervals in FRVT2002.
More recent work on the evaluation approaches, [Micheals-03], investigated that the choices for grouping/clustering used in the evaluation and developed an important extensions of STRAT technique to allow not just estimation of uncertainty in evaluations, but to also support empirical validation of the potential grouping assumptions. The following graph shows a meta-experiment where over 256×1440 facial images were used to evaluate different grouping and evaluation techniques. (The data is from clear weather days using the Photohead technique we developed for evaluation weather effects.). The approach considered three approach, one based on Stratified sampling, one based on cluster sampling techniques, and one based on Bernoulli assumptions, and then looked at various clusters/strata. This work is the only know vision system evaluation to use large scale controlled experiments to validate the evaluation paradigm and the assumptions used in that paradigm.
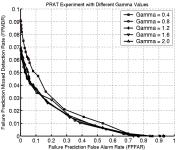
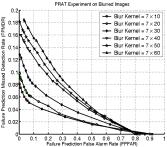
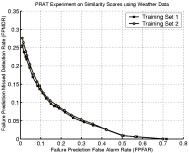
Continuing on beyond evaluation, our project also explored prediction of recognition system failure. While predicting failure at an algorithm level may do little, at a systems level it opens the door to improved performance by allowing us to capture new images of the subject or to consider fusion of various algorithms or different data sources. The technique uses the similarity scores from the matching process and subjects them to different learning techniques to predict when an image would fail. The first approach was just focused on prediction of failure, and was tested with FaceIT recognition data using the various simulations discussed earlier as well as on data from different weather conditions. As the prediction is itself a “classifier”, we present some example ROC curves showing the tradeoff in Miss detection rates (i.e., how often it did not predict recognition failure when it did occur) vs. False Prediction False Alarm (i.e., the algorithm predicts failure but the face is correctly recognized). The four graphs show predictions for different Gammas, Blurring and the real weather data sets. For gamma you may recall there was little variation in recognition rates, and as you can see little variation in the failure prediction ability. It is worth noting that the system can predict 96% of the failures (.04 FPMDR) with a false alarm rate of 10%. For the blur experiments failure prediction degrades with increased blur, but for moderate blur (sigma=3.0 pixels) the prediction rates are still above 90% with a false alarm rate of 10%. For the real weather data it was tested on two different training sets, providing very similar performance. The failure prediction performance was now, however, as good as on the synthetic variations, probably because weather introduces a wider range of variations that may not have been well represented in the training sets.
|
|
|
|
|||
The prediction accuracy does not directly translate to improved system performance, as the individual may simply be difficult to recognize so even if we acquire multiple images they may not be well recognized. However being able to predict when new images would be helpful with over 90% accuracy could significantly improve overall face recognition performance.

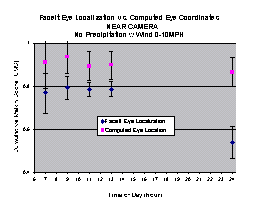 The final prediction work looked not only at predicting, but examined the potential causes. Our evaluations were suggesting very significant problems on outdoor images and eventually we hypothesized that the cause was the eye-localization. We did experiments [Riokia-Boult-03] that confirmed this and also showed that corrected eye locations would statistically significantly improve the results. The experiments used FaceIt, Elastic Bunch Graph Matching (EBGM) and PCA implementations and showed them all to be quite sensitive to this effect. Example graphs for FaceIT are shown for both “weather” induced effects and for lighting/pose effects. For the weather effects the images are from our PhotoHead datasets where we augmented the images with fudical marks so we could recompute the “ground-truth” eye locations after re-imaging through the weather. Using the corrected eye locations as inputs we see recognition rates in the 90+%, showing the recognition failures are largely attributable to eye localization failures.
The final prediction work looked not only at predicting, but examined the potential causes. Our evaluations were suggesting very significant problems on outdoor images and eventually we hypothesized that the cause was the eye-localization. We did experiments [Riokia-Boult-03] that confirmed this and also showed that corrected eye locations would statistically significantly improve the results. The experiments used FaceIt, Elastic Bunch Graph Matching (EBGM) and PCA implementations and showed them all to be quite sensitive to this effect. Example graphs for FaceIT are shown for both “weather” induced effects and for lighting/pose effects. For the weather effects the images are from our PhotoHead datasets where we augmented the images with fudical marks so we could recompute the “ground-truth” eye locations after re-imaging through the weather. Using the corrected eye locations as inputs we see recognition rates in the 90+%, showing the recognition failures are largely attributable to eye localization failures.
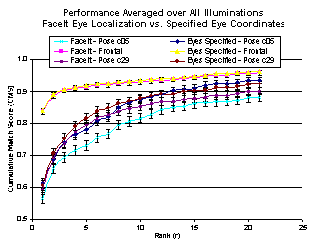
To show the effects are not just “weather” related we also did an analysis of the PIE dataset from CMU. A total of 68 individuals from the CMU PIE database with neutral expressions, taken using 21 illuminations and for each of 3 poses were used in this experiment. Using front profile images in the gallery with room lights on, FaceIt performance was measured on probes each consisting of the 68 individuals under 21×3=63 different combinations of illumination and pose. Illuminations resulting in the darkest images were not used to insure that FaceIt would be able to properly locate the face.
Poses used were front profile and the two closest poses on either side of the front profile. FaceIt was run twice, once using FaceIt eye localization, and a second time using the PIE specified eye coordinates. Again the results show that eye localization is a statically significant cause of recognition failure.
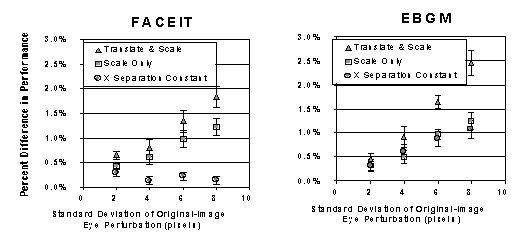
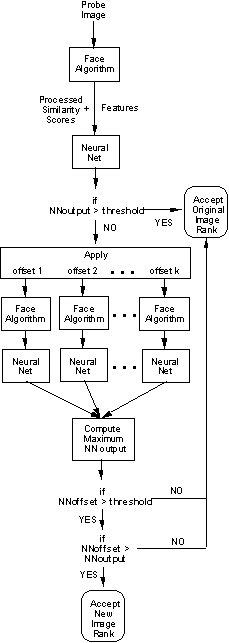 But predicting failure and knowing the eye localization may often be the cause lead to the development of a new approach mixing prediction of failure with perturbations of the eye-locations and re-recognition, fusing the results based on our predictions. The accompanying flow chart shows the basic algorithms. We developed a Neural-Net based failure prediction algorithm and, when it predicts failure then rerun face recognition with “perturbed” eye locations and then rerun the failure prediction on the outputs and keeps the result least likely to fail. For the experiments we used weather-induced artifacts and consider a few limited perturbations models including overall scaling, X-dimension separation (IPD) and full translation and scaling. We also separated the evaluation using the known perturbations and show the percentage increase in performance with the new approach (and 95% confidence intervals).
But predicting failure and knowing the eye localization may often be the cause lead to the development of a new approach mixing prediction of failure with perturbations of the eye-locations and re-recognition, fusing the results based on our predictions. The accompanying flow chart shows the basic algorithms. We developed a Neural-Net based failure prediction algorithm and, when it predicts failure then rerun face recognition with “perturbed” eye locations and then rerun the failure prediction on the outputs and keeps the result least likely to fail. For the experiments we used weather-induced artifacts and consider a few limited perturbations models including overall scaling, X-dimension separation (IPD) and full translation and scaling. We also separated the evaluation using the known perturbations and show the percentage increase in performance with the new approach (and 95% confidence intervals).
|
|
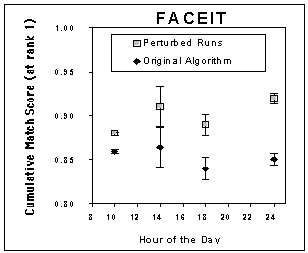
We also present a graph showing the overall impact of the perturbation based algorithm on real recognition rates for FaceIT using outdoor weather data at various times of the day. Once again the impact is statically significant.
Conclusions
The Flexible imaging project has examined many of the root sensor related issues in human identification at a distance, developed and tested new sensors, developed new approaches for flexible imaging sensor design, developed new algorithms for super-resolution and shown it effective, developed new approached to evaluation and the prediction of face-recognition system failure.
Publications
“Programmable Imaging using a Digital Micromirror Array”
V. Branzoi, S.K. Nayar and T. E. Boult,
To appear, IEEE Computer Vision and Pattern Recognition, June 2004.
“Understanding Images of Graphical User Interfaces: A new approach to activity recognition for visual surveillance”.
Yu Li and T. Boult,
To appear IEEE Workshop on Event Detection, June 2004.
“Omni-directional Visual Surveillance”,
T.E. Boult, X. Gao, R. Micheals, and M. Eckmann,
Image and Vision Computing Special issue on surveillance, Elsevier House, May 2004.
“Adaptive Dynamic Range Imaging: Optical Control of Pixel Exposures Over Space and Time”
S. K. Nayar and V. Branzoi
In Proc. International Conference on Computer Vision (ICCV), October 2003.
“High Dynamic Range from Multiple Images: Which Exposures to Combine?”
M. D. Grossberg and S. K. Nayar
In Proc. ICCV Workshop on Color and Photometric Methods in Computer Vision (CPMCV), October 2003.
“Generalized Mosaicing: High Dynamic Range in a Wide Field of View”
Y. Y. Schechner and S. K. Nayar
International Journal of Computer Vision, Vol 53, No. 3, July 2003
“A Perspective on Distortions”
R. Swaminathan and S. K. Nayar
In Proc. IEEE Computer Vision and Pattern Recognition (CVPR),
Wisconsin, June 2003.
“What is the Space of Camera Response Functions?”
M. D. Grossberg and S. K. Nayar
In Proc. IEEE Computer Vision and Pattern Recognition (CVPR), June 2003.
“The Eyes have it”,
T. Riopkia and T.E. Boult,
ACM Workshop on Biometrics, Berkeley CA, September 2003.
“Understanding Images of Graphical User Interfaces”.
Yu Li and TE. Boult,
ACM UIST 2003, Oct 2003.
“What can be Known about the Radiometric Response Function from Images ?”
Michael D. Grossberg and Shree K. Nayar
Proc. of European Conference on Computer Vision (ECCV) May 2002.
“Assorted Pixels : Multi-Sampled Imaging With Structural Models”
Shree K. Nayar and Srinivasa G. Narasimhan
Proc. of European Conference on Computer Vision (ECCV) , May 2002.
Efficient Evaluation of Classification and Recognition Systems” ,
R.J. Micheals and T.E. Boult,
Proc. of the IEEE Conference on Computer Vision and Pattern Recognition, Dec 2001.
“Super-Resolution via Image Warping”,
T.E. Boult, M.C. Chiang and R.J. Micheals,
Chapter 6 in Super-Resolution Imaging, S. S.Chaudhuri (ed.) ISBN 0-7923-7471-1, Kluwer Academic Publishers, 2001.
“A Stratified Methodology for Classifier and Recognizer Evaluation”,
R.J. Micheals, T.E. Boult,
IEEE Workshop on Empirical Evaluation Methods in Computer Vision, Dec 2001.
“Caustics of Catadioptric Cameras”
Rahul Swaminathan, Michael D. Grossberg and Shree K. Nayar
Proc. of IEEE International Conference on Computer Vision, July 2001.
“A General Imaging Model and a Method for Finding its Parameters”
Michael D. Grossberg and Shree K. Nayar
Proc. of IEEE International Conference on Computer Vision, July 2001.