
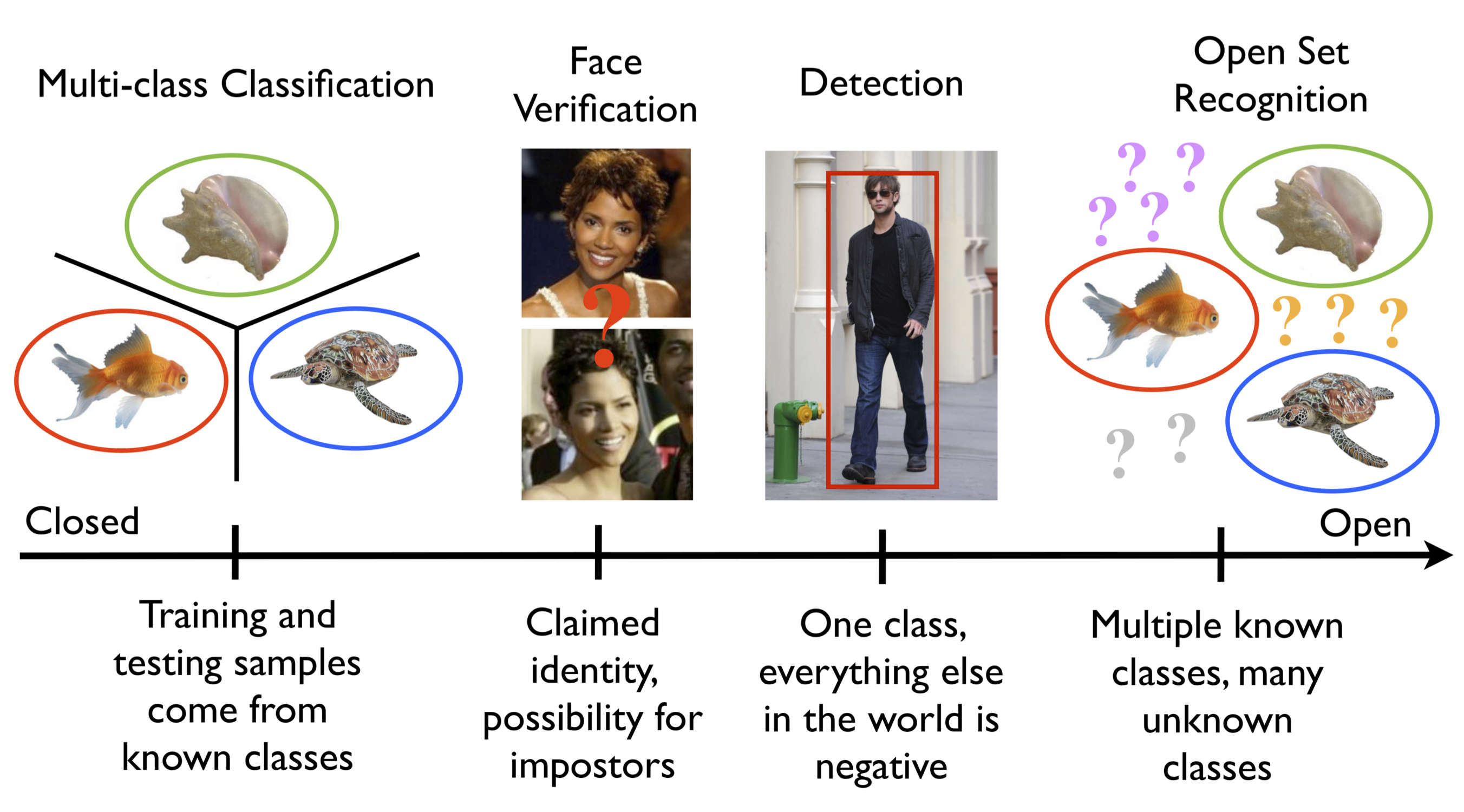
Open set recognition happens when negative classes are ill-sampled or not sampled at all during training appear in system operation or testing. Vision and machine learning researchers have made great progress and are tackling bigger and bigger datasets, but have done so in a closed set paradigm. As we reduce the assumptions and controls and move toward real problems, we must face up to the fact that while we may sample tens of thousands of positive classes, we cannot sample all possible negatives – our world is effectively open and we need to embrace its openness.
1) Designing for open set recognition — designing classifiers in the face of data with uncertain or ill-defined category membership
2) Meta-recognition — bringing a statistically-grounded probabilistic interpretation to support recognition
3) Projective imputation and bias correction for missing data
We present preliminary work, using linear models, on each of the three. The new theoretical constructions for the three areas provides a strong basis and the preliminary work, for each of the three areas, is at or significantly advancing the state of the art. The proposed work will expand on this strong basis, unify and integrate them and support non-linear kernels and optimized open set multiclass recognition.
We call this effort “OpenVision” for two reasons:
1) We present a vision for open set recognition problems that will advance core science in vision and machine
learning.
2) We will develop open source recognition tools that will apply across many domains.
This briefly summarizes our most significant results: in 1-vs-set machines, open set kernel machines and open world recognition.
Open Set via 1-vs-Set Machine
“Towards Open Set Recognition,”
Walter J. Scheirer, Anderson Rocha, Archana Sapkota, Terrance E. Boult, IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI),
July 2013.
[pdf] [bibtex]
Abstract to Towards Open Set Recognition: To date, almost all experimental evaluations of machine learning-based recognition algorithms in computer vision have taken the form of “closed set” recognition, whereby all testing classes are known at training time. A more realistic scenario for vision applications is “open set” recognition, where incomplete knowledge of the world is present at training time, and unknown classes can be submitted to an algorithm during testing. This work explores the nature of open set recognition, and formalizes its definition as a constrained minimization problem.
The open set recognition problem is not well addressed by existing algorithms because it requires strong generalization. As a step towards a solution, we introduce a novel “1-vs-Set Machine,” which sculpts a decision space from the marginal distances of a 1-class or binary SVM with a linear kernel. This methodology applies to several different applications in computer vision where open set recognition is a challenging problem, including object recognition and face verification. We consider both in this work, with large scale cross-dataset experiments performed over the Caltech 256 and ImageNet sets, as well as face matching experiments performed over the Labeled Faces in the Wild set. The experiments highlight the effectiveness of machines adapted for open set evaluation compared to existing 1-class and binary SVMs for the same tasks.
Index Terms. Open Set Recognition, 1-vs-Set Machine, Machine Learning, Object Recognition, Face Verification, Support Vector Machines.
- “Animal Recognition in the Mojave Desert: Vision Tools for Field Biologists,” (Best Paper Award)
Michael J. Wilber, Walter J. Scheirer, Phil Leitner, Brian Heflin, James Zott, Daniel Reinke, David Delaney, Terrance E. Boult, Proceedings of the IEEE Workshop on the Applications of Computer Vision (WACV),
January 2013.
[pdf] [bibtex] - “Detecting and Classifying Scars, Marks, and Tattoos Found in the Wild,”
Brian Heflin, Walter J. Scheirer, Terrance E. Boult, Proceedings of the IEEE International Conference on Biometrics: Theory, Applications and Systems (BTAS),
September 2012.
[pdf] [bibtex]
Software
Clone the source from github: libSVM-onevset
UPDATE: to support our CVPR2015 paper on “Toward Open World”, we wanted to compare with 1-vs-set, but the libSVM-onevset version was too slow..(weeks) and so we developed a multi-class extension to liblinear. Now Clone the new source from https://github.com/Vastlab/liblinear.git
More information and data can be found at
http://www.metarecognition.com/openset/
Open-set with Kernels
We have extended the Open set paradigm with two different papers using Kernel Machines and a much more comprehensive theory. In these papers we introduce a new model Compact Ababating Probability and show how thresholding it can manage openspace risk. We also introduce the first probability calibration for a “one-class” model and produce a discriminatively trained but one-class like model — the Probability of Inclusion (Pi-SVM). We also introduce as generally more accurate and more expensive W-SVM model that combines Probability of Inclusion, Probability of Exclusion and a one-class mode. See the following papers. Source code is available at https://github.com/ljain2/libsvm-openset.
- Probability Models for Open Set Recognition,”
Walter J. Scheirer, Lalit P. Jain, Terrance E. Boult,
IEEE Transactions on Pattern Analysis and Machine Intelligence (T-PAMI),
November 2014.
[pdf] [supp. material] [errata][bibtex] - “Multi-Class Open Set Recognition Using Probability of Inclusion,”
Lalit P. Jain, Walter J. Scheirer, Terrance E. Boult,
Proceedings of the European Conference on Computer Vision (ECCV),
September 2014.
[pdf] [supp. material][bibtex]