
Video surveillance is watching an area for significant events. Perimeter security generally requires watching areas that afford trespassers reasonable cover and concealment. Almost by definition such ``interesting'' areas have limited visibility distance. These situations call for a wide field of view, and are a natural application for omni-directional VSAM.
This paper describes an omni-directional tracking system. We then discuss some domain application constraints and background on the paracamera. We then go through the basic components of the frame-rate Lehigh Omni-directional Tracking System (LOTS) and describe some of its unique features. We end with a summary of an external evaluation of the system.
Figure 1: Tracking system with a single perspective ``target'' window. (Left-right reversal because of mirror.) Note figure is also link to a MPEG movie of the tracker in action. (Quality lost because of need to keep down MPEG size, this one is 18Megs and shows 4 perspective windows...)
While it would be possible to unwarp in multiple directions and then do tracking, it would add considerable expense. Therefore, we are working directly in the complex geometry of the paraimage.
Note that the ``spatial resolution'' of the paraimage is not uniform. While it may seem counter intuitive, the spatial resolution of the paraimages is greatest along the horizon, just where objects are most distant. While the process scales to any size imager, the current systems use 640x480 NTSC (or 756x568 PAL) cameras. If we image the whole hemisphere, the spatial resolution along the horizon is [(240 pixels * 2*p)/ 360 degrees] = 4.2 [pixels/ degrees] (5.1 PAL) which is 14.3 arc-minutes per pixel (11.8 PAL). If we zoom in on the mirror, cutting off a small part of it, to increase the captured mirror diameter to 640 pixels (756 PAL), we can achieve 10.7 (6.6 PAL) arc-minutes per pixel.
As a point of comparison, let us consider a traditional ``wide-angle'' perspective camera. Allowing for a small overlap to continually track objects, it would take 3 cameras with about a 150° horizontal field-of-view (FOV) to watch the horizon. Note that each of these would have [640pixels/ 150degrees] = 4.2[pixels/ degrees], i.e. about the same as the Paracamera. Clearly, the traditional cameras would need more hardware and computation.
Every surveillance system must consider the tradeoff between resolution and FOV. The paracamera's unique design yields what may be a new pareto optimal design choice in the resolution/FOV trade-off. We have the horizontal resolution of a 150° camera but cover the full 360° of the horizon.
With a wide field of view, objects to be tracked will cover only a small number of pixels. With 4.2 pixels per degree, a target of dimension 0.5m by 2.0m, at 50m is approximately 2 pixels by 8 pixels, i.e. 16 pixels per person. At 30m, it yields approximately 32 pixels per person, presuming ideal imaging. Realistic tracking in a such a wide field of view requires the processing of the full resolution image with a sensitive yet robust algorithm.
Our tracker is running under Linux using MMX enabled processors. The code described herein runs at 30fps on a 266 Mhz K6 with 32MB of memory and a PCI frame-grabber. We have demonstrated a smaller system based on a 166MMX in a Compact-PCI housing (12''x5''x5'') that tracks at 15fps. We are also porting the tracker to our augmented Remote Reality ``wearable'' (a low-power 133MMX based system), see [].
While the system is capturing 16 bit YUV data, we are currently using only the Y channel, to allow the same system to be used with monochrome night-vision devices. Color would enhance tracking in urban scenes, but adds little for camouflaged targets in the woods and fields.
![]()
Figure 2: Main modules and data flow for LOTS System.
Most background subtraction based systems use temporal integration to adapt to changing lighting, i.e. Bt+1 = a It + (1-a) Bt , where a is the blending parameter, Bt is the background image at time t and It is the image at time t. Some systems also utilize it to provide a streaking-effect or ``motion history'' which can increase connectivity and apparent size for fast moving targets.
However, because of the very gradual image change inherent with our target's slow speed and small size, we use a very slow temporal integration. The system supports pixel updates with the effective integration (blending) factor from a = 0.25 (our fastest integration) down to a = 0.0000610351, with a = 0.0078125 as the default value. Using such small fractions is, of course, numerically unstable, especially when using byte-images. For the sake of both speed and numerical accuracy the system does not update the background images every frame, rather it reduces the rate at which the background is updated such that the multiplicative blending factor is at least 1/32. For example an effective integration factor of 0.00006 is achieved by adding in 1/32 of the new frame, every 512 frames.
Given a target that differs from a mid-gray background by 32, and a ``threshold'' of 16, this takes between 2 to 4096 frames (1/15 of a second to 2+ minutes) for the target to become part of the background. To further reduce target pixels blending into their background, such pixels are updated even less frequently, generally 0.25 times as often. The result is that moderate contrast targets, once detected, are ``tracked'' for between 1 second and 8 minutes, and low contrast targets generally last a minute or two.
Our approach to adaption gives the detection system an important asymmetric behavior: it is very quick to acquire targets, but once detected, its very slow to give them up. This is very important for low-contrast slow moving targets, e.g. the sniper in figure . The downside of this approach is that some false alarms tend to persist, and when objects that are stationary for a long time depart, they leave behind long-lasting ghosts. How these issues are handled will be discussed later.
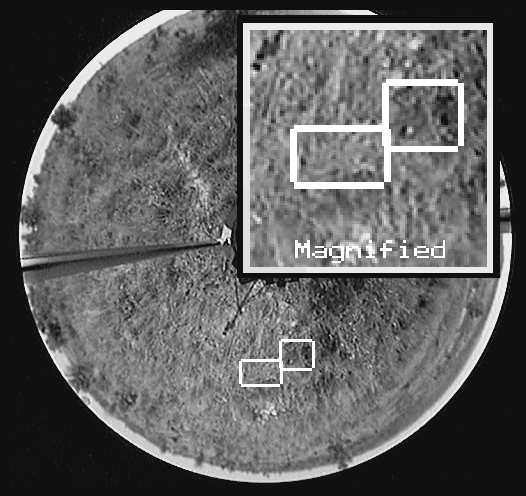
Figure 3: Tracking a sniper moving in the grass. The camouflage is quite good, but careful background differencing shows the location. Frame-to-frame motion is small, a good sniper may take crawl at under .5 meters per minute and be motionless for minutes at a time. Note figure is also link to a MPEG movie of the tracker in action. (Quality lost because of need to keep down MPEG size, this one is 4Megs...)
Those with experience in these types of systems might be wondering how this can really work. While even the slowest of the above update rates is sufficiently fast for gradual lighting changes such as normal sun motion, it will not adapt fast enough to handle rapid lighting changes, e.g., the sun going behind a cloud. This observation is correct and to handle these other situations explicit ``lighting change heuristics'' are applied at a later stage (after connected component labeling). These heuristics will be described later.
The second significant feature of our background technique is that there is not a single background model, but 3 different backgrounds models, i.e. pixels can have 3 different ``backgrounds''. This is a significant advantage for ignoring real but contextually insignificant motions such as moving trees/brush. When the trees move they occlude/disocclude the scene behind them and the system ends up building models for both backgrounds. The testing against the secondary background is done on a per pixel basis but adds very minimal cost because it is only consulted when the pixel is significantly above primary background, which is very infrequent. The disadvantages of these two background models are the additional memory requirement, and the loss of sensitivity if the secondary background is updated poorly.
Currently, we acquire the second background model by an initial batch learning with interactive supervised learning when false-alarms occur. We are investigating more automatic methods, which involve feedback from the high-level tracking components of the system. If false alarms occur during processing, the user may request that particular regions update their secondary background model to prevent further false alarms by that target. We also point out that the secondary background generally does not update frequently enough to allow good ``variation'' estimates and we do not maintain a secondary variation image. However, whenever the update value for a pixel's is very different from its current value, we increase the pixels variation and replace, rather than blend the values. The latter helps when there are really 3 backgrounds that need to be modeled, at least we get 2 of them rather then one plus a mixture of the other two.
Both the primary and secondary backgrounds are updated via the blending model to allow them to track slow lighting changes. Unfortunately, the blending also means that targets leave ``ghosts'' and false alarms that are quite persistent. To help handle these problems the system has a third background image (called the old-image) that is not updated via a blending model. Rather it is a pure copy of an old image, except that targets within that image are tagged with a value of zero.3 This old image is always at between 9000-1800 frames (5-10 min) old and for efficient implementation purposes switches between two images. As described in section , comparison against this old-image is not done pixel by pixel, but rather it is incorporated into the cleaning phase.

Figure 4: Tracking soldiers moving in the woods at Ft. Benning GA. Each box is on a moving target. The multi-background modeling and thresholding with hysteresis are important to ignore the many moving trees in this scene and help connect the soldiers even when their camouflage is nearly the same intensity as the background. Note figure is also link to a MPEG movie of the tracker in action. (Quality lost because of need to keep down MPEG size, this one is 16Megs and shows 1 perspective window1...)
The background subtraction uses a two level thresholding-with-hysteresis, i.e., all pixels in a region must be above the low threshold and must be connected to at least one pixel above the high threshold. The low threshold is the sum of the global threshold and the per-pixel variation. The high threshold is currently set at 4 times the low threshold; if the variances were true variances and the noise was Gaussian this would assure us that at least part of each target was, with > 99.9% confidence, not noise. The two level thresholds are maintained by initially computing the difference with the low threshold. If that is exceeded we test the high threshold, and set some high order bits in the ``low-resolution'' image to be described in the next section.
To keep the subsequent processing fast, the thresholding process keeps pointers to the initial and final pixels, per row, that are above the low threshold. Rows with nothing above threshold (usually 80% or more of the image) are skipped in subsequent processing.
Because we expect only a small growth in the number of pixels above threshold, the thresholding counts the number of pixels above threshold and checks this assumption. If it is violated, it is probably a rapid lighting change or a radical camera motion.4 The system attempts to handle radical growth by presuming it to be a rapid lighting change and temporarily increases both the global threshold and the allowed growth rate. This attempt to increase the thresholds is tried twice. If it is successful in reducing the growth, we proceed as usual except we force an update of non-target regions with a blending factor much larger than usual.
If after raising the threshold a few times we still detect that the number of pixels differing from the backgrounds is growing too fast then we presume the growth must be because of camera motion.5 To handle camera motion we:
While thresholding, we also build a lower resolution image of those pixels above threshold. The pixels in this parent (low resolution) image maintain a count of how many of its associated children (high resolution pixels) were above threshold. Since resolution is reduced by a factor of 4 in each direction, the parent image contains values between 0 and 16, which allow us to have accurate low-level area counts for thresholding. For example a region which connects 4 ``parent-level'' pixels might have a total area of support of only 12 pixels in the high resolution image (and would not be connected at that level). The high-order bits of the low resolution image were also set when the pixel was above the high threshold. As we add the areas we naturally find out if any were also above the high threshold (we AND with a mask to make sure they don't overflow). In this way the thresholding-with-hysteresis is computed along the way in the connected component labeling processes, without the need for a second thresholding pass.
The connected component phase is only applied to the parent image. In addition to the speedup due to data reduction, this resolution reduction also has the effect of filling in many small gaps. The gap filling is spatially varying; the maximum distance between ``neighbors'' varies from 4 to 8 pixels. While not as ``uniform'' as morphological processing, it is considerably faster and has shown itself to be very effective.
After the connected components, we have a collection of regions that are different from the background. The next phase is to clean up noise regions and some expected, but insignificant, differences. There are three different cleaning algorithms: size, lighting normalized and unoccluded region.
The goal of area thresholding is to remove noise regions. The area thresholds, which are applied per region, use the accumulated pixel counts from the parent image. The area is not the number of pixels in the low resolution connected components image, but rather the total count of high-resolution pixels above the ``low'' threshold that are in the region. This allows the system to detect (and retain) a human target at 50m, i.e., a 2 pixels by 8 pixels region in the full resolution paraimage. There is also a maximum threshold to avoid large slow-moving shadows of clouds.
The second and third cleanings use normalized intensity data. This is done by computing the average pixel intensity within the target computed in three images: the input, the primary background, and the old-image. Computations are then scaled by ratios of these values. We compute the normalize factor across the whole region rather than doing a more accurate, but more expensive, local normalization. In our experience to date, this has been sufficient for small and moderate size regions, while large regions are usually thresholded away by the area test.
The second cleaning looks for local lighting variations, e.g. small cloud patches, sunlight filtered through the trees, etc. We do this by redoing the ``thresholding-with-hysteresis'' for the region again but this time using normalized background intensity.
The third cleaning phase is to see if it is a region where a moving target has disoccluded the background. This is done by doing a thresholding-with-hysteresis comparison against the normalized old image.
After handling the spatio-temporal connected regions, only a small number of regions remain unlabeled. Therefore, the system can spend considerably more time trying to match up these regions. It looks to merge new regions with near-by regions that have strong temporal associations. It also looks to connect new regions with regions that were not in the previous frame but that had been tracked in earlier frames and disappeared. Both of these more complex matchings use a mixture of spatial proximity and feature similarities.

Figure 5: Example from VSAM IFD demo with 3 perspective windows tracking the top 3 targets. In the paraimagem targets have trails showing their recent ``path''.
Another feature of the user interface (UI) is the ability to select both regions of interest and regions of disinterest (``always'' ignored). The latter can be used to exclude targets in areas where motion is expected, but insignificant.
The UI can show a ``density'' of targets over the recent past, can limit display to targets with a particular certainty, and can toggle between targets having ``trails''. These help in isolating regions of potential problem, and in understanding the nature of a target.
If a target perspective window contains a ``false alarm'', the user can provide runtime feedback and have it ``ignore'' that target and update the multi-background model to attempt to ignore it in the future.
The LOTS system has parameters allowing it to be tuned to different conditions. A number of predefined scenarios can be used to set these system parameters.
The single-viewpoint constraint of the paracamera makes it straightforward to ``back-project'' a ray into the world, and also allows a simple calibration process. Given three 3D world coordinate points on the ground plane, we can solve for the transform from paraimage coordinates to the world coordinates of the point on the ground plane that projects to that a given image coordinate. The detailed equations for the relation are beyond the scope of this paper.
Given the calibration points, we precompute a ``map'' that gives the 3D coordinates of the back-projection of each pixel in the paraimage, thus runtime computation is a trivial table lookup. When the calibration points are chosen near the ``horizon'', the resulting 3D projection is usually quite good. Localization of the calibration points, the presumption of a ground plane (rather than a complex surface) and the ability to localize a target are the limiting factors.
A final component of our ongoing efforts is the multi-camera coordination and a fully networked system. With this extension, the targets are tracked in local sensor processing unit (SPU) (computer/camera pair). As mentioned before each paracamera SPU has a local ``scheduler'' for the most significant targets. Target information and significant video clips are integrated and displayed by a networked display controller (NDC). The NDC is in charge of network bandwidth allocations and chooses amount the potential video streams from the various SPUs . The goal is to have one networked computer connected to 5-20 paracameras with all of the ``significant events'' being viewed on the NDC.
One of the design constraints in our development was the ability of the protocol to scale to a large numbers of sensors each with a large number of targets while not saturating the network. It has been demonstrated with wireless communication connecting the paracamera SPU to a mobile display unit. When running in network mode the code can be slowed down as network ``targets'' are sent only 4-5 times per second. This may allow slower, lower power processors to be used or multiple paracameras on each processor.
The network protocol design underwent a number of iterations and in mid 1998 we coordinated with CMU on a compromised protocol which incorporated key ideas from both the original CMU and the new Lehigh design. The result was less bandwidth efficient but considerably easier to implement/use and something we could share among researchers for the DARPA VSAM program, see [] for details.
A paracamera SPU was a part of the VSAM integrated feasibility demonstration [] where its targets were coordinated with a number of CMU pan-tilt-zoom type SPUs. The ``mini-OCU'' of the paracamera controlled 3 perspective views, but 3D target locations of the top 7 targets were sent to the coordinating CMU processor.
Researchers at the Institute for Defense Analysis have done some preliminary analysis of LOTS, as of Aug. 1998, and we report on their evaluation.
The analysis showed approximately 95% detection rates (ranging from 100% down to 87%) and a false-alarm-rates ranging from .15FA per min to 1.7FA per min. Almost all detections were considered ``immediate'', with only the most difficult cases taking longer than a second. The scenarios evaluated included: short indoor segments, two urban/street scenes, two different wooded settings, a town edge and tree-line and a sniper in a grass field. These evaluations did not include the use of any confidence measures, nor did they allow for incremental learning or adaptive feedback on false alarms.
At the time of this initial external evaluation, the only cleaning phase was area based. A large fraction of detected false alarms were small to moderate sized locations with lighting related changes, e.g. small sun patches filtering through the trees or shadows. In a wide field of view, many of these appear very much like a person emerging from occlusion. The ``ghosting'' of targets was also noted in their report. This feedback lead to additional cleaning phases. The confidence measures, feedback, and new cleaning processes, will be part of a reevaluation scheduled for Jan. or Feb. 1999.
2 Cyclovision, Inc has an exclusive license on this patented design, see www.cyclovision.com.
3 The capture card produces a minimum valid gray value of 16
4 In urban settings with nearby buildings, its possible for disocclusion of a large object to cause a moderate growth. Therefore the growth percentage is a system parameter.
5 In most of our data collection scenarios the camera is mounted in a tree and is subject to tree motion.
6 While generally correct, this may incorrectly connect/label individuals within a closely packed fast-moving group; While not a problem for targets at walking speeds, it can occur for vehicles. Corrections for this problem are being investigated.