Plausible reality for real-time
immersion in the virtual arena
Simon M. Rowe
Canon Research Centre Europe Ltd
1 Occam Court
Guildford
GU2 5YJ
UK
smr@cre.canon.co.uk
Abstract
|
| Over the last three
years there has been increased interest in photo-realistic
modelling and rendering techniques and a surge in
popularity of image-based rendering. These techniques aim
to accurately model reality in order to generate virtual
imagery that is indistinguishable from it. In this paper
we introduce the concept of plausible reality. The aim of
plausible reality is also to generate virtual imagery
that is indistinguishable from reality, but without
necessarily duplicating it. The key benefit of plausible
reality over duplicating reality is that it can be done
in real-time with simple computer vision techniques. We
demonstrate a plausible reality system running real-time
on an off-the-shelf PC. |
1 Introduction
There has been considerable work in recent
years into generating accurate photo-realistic 3D models and
images [7]. These techniques aim to accurately model the shape
and appearance of the real world. For many applications, this is
over-kill: if a user is looking at a computer-generated model,
they generally don't have the real world there to compare it to.
It is enough for the model to look realistic. As long as this
computer generated reality is plausible (and in some sense
reflects actual reality), the user is happy, even if the image
they are seeing is computer generated and not pixel-equivalent to
an original video stream.
The fact that reproducing reality is
unnecessary (and occasionally undesirable) has been exploited by
some industries. Photographs in adverts have often been altered
to enhance their appearance , or to hide undesirable elements,
film sets often exaggerate geometry in order to achieve a more
dramatic impact - they are creating a plausible reality. The fact
that (for some applications) it is enough to create a plausible
reality rather than reproducing reality allows a far greater
range of computer vision techniques to be used to create the
reality, and assumptions/approximations to be incorporated. Real-time
applications that were previously impossible suddenly become
possible.
By way of example, the rest of this paper
describes one such application: creating a moving 3D model of a
sports game live using only standard PC hardware.
Background and motivation
Watching live television can be a frustrating
experience - often the director's idea of what is interesting
doesn't fit with what the viewer wants to see, the director is
limited by the physical locations of cameras which are covering
an event. Digital TV offers the opportunity to give more control
and flexibility to the viewer.
This paper details a system that gives viewers
more control over what they see, and, from where they see it.
Each viewer has control over a virtual camera through
which they view the live action. They are able to move the camera’s
position at will in order to get the best view of the action. The
virtual camera is actually viewing a simple animated 3D
model of the live action.
Throughout this paper the example of a football
(soccer) game is used. The techniques and system described (3DV)
can obviously be applied to a much wider range of subjects.
The techniques used in this paper are not
bleeding-edge computer vision. What this paper serves to show is
that, by combining simple, well proven and understood techniques
with a little prior application knowledge, computer vision can
add significant value to multi-media at a low computational and
financial cost.
The 3DV system
As our aim is to produce a model that is
plausibly close to reality, rather than exactly correct. This
means we can apply a number of constraints or assumptions to
simplify the mathematics. The assumptions are largely based
around the physical laws that govern human motions and the
imaging conditions:
- People stand on the ground
- People stand vertically (as opposed to
say, leaning forwards 45o)
- The lowest point on the image of the
person is where they are touching the ground
- People are affine and planar (i.e.
the physical cameras are located at a relatively large
distance from the players).
While most of these assumptions are clearly
true most of the time, assumptions 1 and 2 can be violated for
short periods of time, such as when a player is jumping up, or
falls over. In circumstances such as these, the 3D model produced
by our system will be instantaneously wrong, however the system
recovers quickly as the player either lands or falls flat onto
the ground. Assumption 3 is broken if the video camera suddenly
undergoes cyclo-torsion. Assumption 4 is basically observing that
the magnitude of the depth of a person (typically 8inches –2
feet) is much smaller than the distance from which cameras are
typically viewing them (often in the range of 100feet). This
assumption means that we can represent people as planes in our 3D
model without losing significant realism - provided we align the
plane appropriately. Although assumption 4 sounds severe, it has
been found to work well in practice - as is shown in Figure 1.

|

|

|

|
| Figure 1: This figure
shows several views of the 3D model obtained by
processing the video in Figure 2. The views are shown
from a variety of virtual camera positions. As can be
seen, representing each player as a texture mapped,
planar, figure is remarkably effective. An MPEG
demonstrating the system can be found here.
|
The 3DV system consists of a number of
processing stages that convert a 2D video signal to a plausible 3D
computer model. The processing complexity is low enough that a
single camera version of the entire system can be implemented to
run in real-time on a standard 300MHz Pentium PC. Much of the
processing in the system is inherently parallelisable - if
multiple cameras are used to provide a full 360o
visible model, the processing can be shared over multiple PCs to
keep real-time performance. The algorithmic steps used by the
system can be summarised as:
- Determine location, shape and textures
of players/ball in the video
- Determine 3D location of players on the
playing field
- Produce 3D representation of field/players
- Broadcast model to digital TV
- Render
The more interesting of these steps (1,2 and 3)
are now explained in a little more detail in the following
sections.
2. Extracting players from a video sequence
The first stage of the system is to locate the
moving objects in a video frame. There are a variety of
approaches that could be applied to do this, ranging from the
fundamental matrix approach of Torr et al [1], through optic flow
techniques[2] to colour analysis [3]. We implemented Rowe's
statistical background model [2] as a simple technique that works
even if the camera pans & tilts (provided the rotations are
known).
The technique involves taking several reference
pictures of the ground without any players on it. These pictures
are then analysed and the statistical variation of each pixel's
colour in the background images calculated - this is used to
develop an appropriate threshold for each part of the image - 10
background images were used in the examples shown in this paper.
It can be seen from Figure 2 that the statistical model produces
a fairly clean segmentation of the moving objects (people) from
the background. In this experiment the camera was stationary,
however [2] shows how the statistical model can be applied to a
pan/tilt (and zoom) camera.
 |
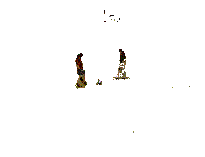 |
Figure 2: This shows a frame of the video,
together with the segmentation obtained using the
statistical background model. The spurious appearance of
the basketball hoop is probably due to the anti-shake
compensation of the camcorder.
|
The result of this operation is an image where
moving regions are represented by pixels with non-zero RGB values.
The shape and texture of the individual moving objects in this
image are extracted using connected component extraction
techniques - these are then passed onto the next stage of the
processing pipeline.
3. Turning 2D player location into 3D
To use the objects extracted in the above stage
they need to be placed into a 3D model of the stadium/sports
ground. In the general case, this would be a hard problem (especially
if restricted to a single view of the scene), however using
assumptions 1 and 3 of section 1.2 and the prior knowledge that
football fields are (or at least should be) planar simplifies the
problem considerably.
In this situation, we can use a simple 2D-2D
mapping to transfer the image of points on the ground-plane, to
actual ground-plane world co-ordinates. In order to calculate the
mapping between image and ground plane, the world co-ordinates of
4 image points are needed, as shown in Figure 3. This allows a 3x3
matrix to be formed which transfers homogeneous image co-ordinates
to homogeneous world co-ordinates. Assumption 3 of the
introduction (no camera cyclo-torsion) means that we know a point
on the ground plane - the point at the bottom of the extracted
blob. This point is used to infer the world co-ordinates of the
blob. Similarly, using the mapping on the lower corners of the
blob allows us to estimate its width in world co-ordinates. By
assuming that the camera is looking horizontally at the object,
and using the aspect ratio of the object on the image plane, we
can hypothesise a plausible height for the object.
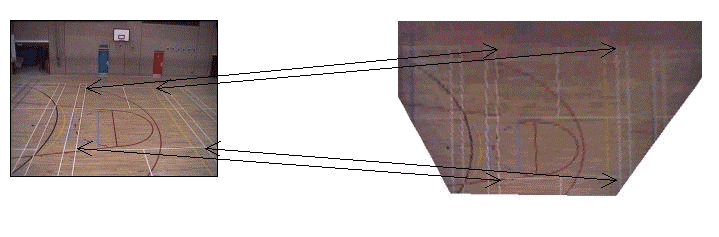 |
| Figure 3: This shows the
4 points used to create the image-world mapping. The
corners of the badminton court in the image (left) are
matched to the corresponding co-ordinates in the 3D model
(right). |
4. Producing a "3D" player
representation from 2D video
Once the shapes of the players’ image, and
their world co-ordinates have been determined, we are left with
the problem of creating a 3D model to represent them. Various
approaches could be applied to form this model. For example, [4]
maps extracted textures onto a cylinder - however this leads to
distorted looking images. If multiple cameras were viewing the
scene from known locations, we can use voxel carving [4], or
colouring [5]. However as we wish our system to work with
commercial video feeds, we cannot assume that we know where the
cameras are. Orad [6] fit fully jointed 3D human models to the
images. However to cope with the limited video resolution and
viewpoints, this is done manually for each frame of video and
consequently is no-where near real-time, and their use of generic
human models means that the scene looks far from realistic.
Our approach is similar to [4] with some
modifications. Instead of a cylinder, we observe that people are
essentially affine (especially when viewed from a camera on the
side of the pitch), and so consequently we can map the images of
the players onto vertical planes with little apparent distortion.
We fix the orientation of the planes to be approximately
perpendicular to the Z-axis of the camera as this is the best
approximation we can make about the player's orientation without
using a much more sophisticated modelling system. Figure 1 shows
several views of the 3D model generated using planes. Provided
the viewer does not stray too far from the direction of the
camera the model looks plausible. As the viewer is (presumably)
not at the ground to compare "ground-truth" to the
computer generated image: producing a plausible representation is
adequate to create the illusion that the viewer is seeing
something which reflects reality.
Figure 4 shows how the single plane object
model is not appropriate when the viewpoint changes to be
orthogonal to the original camera direction - the fact that the
objects are planes becomes increasingly noticeable as the
viewpoint approaches this. Keeping the plane representing the
player perpendicular to the original camera direction is
preferable to rotating them to follow the viewer as this spoils
the illusion by introducing a "moon walking" effect.
 |
 |
| Figure 4: This shows that
our representation of 3D objects breaks down when the
viewpoint changes significantly from the camera's
original view. Introducing more cameras into the ground
would help here. |
5. Limitations of this system
The current system is based on a set of
assumptions which hold true most of the time, but that do
occasionally break down. The plausibility of the system decreases
as the viewpoint moves a large distance away from the original
camera position. In order to produce a full 360o
system, multiple physical cameras would be needed - the 3D viewer
switching between the cameras depending on where the viewer was
viewing the model from.
Currently the system makes no use of temporal
continuity, and assumes that each extracted blob is a single
entity - it has no occlusion handling mechanism.
The system assumes that the entire connected
region obtained using the statistical background model is player
– consequently players have a tendency to walk on top of any
shadow’s they cast.
6. Summary and future work
We have introduced the concept of plausible
reality - the notion that, for some applications, it is
unnecessary to recreate actual reality, but it is enough to
create a reality which look as if it could be real, without
necessarily being real.
The demonstration detailed here shows the
feasibility of producing and displaying a plausible 3D (or at
least 2.5D) model in real-time using only modest computing
hardware. Although none of the techniques used to produce this
video are particularly sophisticated, their combination allows an
impressive demonstration of what is possible today - when the aim
is to recreate a plausible reality, rather than an exact one. The
viewers are able to move their viewing position around a 3D model
produced from a live video sequence, to a large extent freeing
themselves from the limitations normally associated with watching
television.
Future work will be to address the issues
raised in the problems section, making the system more robust and
producing better quality 3D video.
Bibliography
[1] P.H.S.Torr, Geometric Motion
Segmentation and Model Selection, Phil. Trans. R. Soc. Lond.A
(1996) (submitted), (also http://www.robots.ox.ac.uk/~phst/Pap/Royal/m.ps)
[2] Simon Rowe and A.Blake
Statistical mosaics for tracking.. Image and Vision Computing
14 (1996) 549-564, Elsevier
[3] J.D.Crisman Color region tracking for
vehicle guidance In A.Blake and A.Yuile, editors, Active
Vision 107-123. MIT Press, 1993
[4] Patrick Kelly, Arun Katkere, Don Kuramura,
Saied Moezzi, Shankar Chatterjee, and Ramesh Jain. An
Architecture for Multiple Perspective Interactive Video.
Technical Report VCL-95-103, Visual Computing Laboratory,
University of California, San Diego, April 1995.
[5] S.M.Seitz and C.R.Dyer, Photorealistic
Scene Reconstruction by Voxel Coloring, Proc Computer Vision
and Pattern Recognition Conf. 1997, pp 1067-1073
[6] http://www.orad.co.il/
[7] Fitzgibbon, A.W. and Zisserman, A. Automatic
3D Model Acquisition and Generation of New Images from Video
Sequences In Proceedings of European Signal Processing
Conference (EUSIPCO '98), Rhodes, Greece, pages 1261-1269, 1998.